Note: this post has been published also in the Apache Camel blog

Apache Camel K 1.4.0 has just been released!
This is a new major release of Camel K with an improved stability over previous versions, but also adding new features that simplify the overall user experience.
It is based on Camel 3.9.0 and Camel-Quarkus 1.8.1, providing all improvements that they bring, plus much more. In this blog post, we’re going to describe the most important changes.
Embedded Kamelet catalog
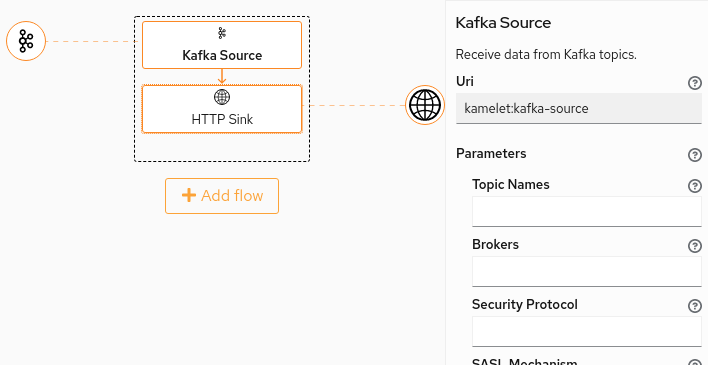
Camel K 1.4.0 comes with an embedded Kamelet catalog containing multiple connectors ready for use.
When installing the operator into a namespace (but also globally in the cluster), the operator installs all the kamelets from the catalog (version 0.2.1), so that any integration can use them directly.
Users can bind them to a specific destination by writing a YAML binding file, as explained in the specific documentation related to each Kamelet.
Or, you can use the new kamel bind command (see below).
Note: it’s easy to write your own Kamelet and publish it to the Apache Catalog. Take a look at the Kamelets developer guide.
Kamel bind command
We’ve added a bind subcommand to the kamel CLI that provides a new way to use Kamelets directly when you need to connect them to Knative channels, Kafka topics and any other endpoint.
E.g. Suppose that you want to get events of earthquakes happening around the world, as JSON objects, in your Knative channel named earthquakes. All you need to do is to install Camel K on your cluster and then execute the following command:
kamel bind earthquake-source channel:earthquakes
This command creates the KameletBinding resource for you and the Camel K operator does the rest to bring that data into your channel. Data is produced using the Earthquake Source Kamelet available in the embedded Katalog.
You can use any other Kamelet from the catalog using the kamel bind command.
You can also target any other Kubernetes reference that is supported by Camel K, for example, sink into a Strimzi KafkaTopic, using a fully qualified reference, for example:
kamel bind earthquake-source kafka.strimzi.io/v1beta1:KafkaTopic:mytopic
Of course, the command also supports plain Camel URIs, which are useful especially when you’re developing a new Kamelet. For example, you can write:
kamel bind earthquake-source log:info?showHeaders=true
And the command will create a binding that just prints to the log the JSON data produced by the source.
Kamel dump command
When users have issues understanding why Camel K is not behaving as expected, they often need to provide useful information about the current state of their cluster, to let Camel K developers investigate the issue and provide a solution or a quick workaround (e.g. in a Github issue, or in the Zulip chat).
Usually, to identify the root cause of an issue, developers need to know things like:
- What routes the user is trying to run
- What the Camel K operator is doing
- What images have been built, which versions of all libraries are they using
- What’s the state of the Camel K custom resources
- What errors do Camel K integration throw when they start
Providing such information has always been hard, but we now have a quick way to obtain all that.
kamel dump status.log
This simple command will store in a text file all the information needed to investigate a possible issue in the cluster. The user can now edit the file to remove sensitive information (which the command may not be able to tell apart), then share it with developers to have much better insights.
Stability and compatibility
We focused a lot on stability and improved compatibility with other tools of the ecosystem.
Knative support (0.22.0) has been improved by fixing compatibility issues that sometimes caused multiple revisions to be present for the same service. We’ve also changed the way channels and brokers are bound to the integrations. Now it’s possible to bind integrations to multiple channels and even create sequences of integrations attached to channels without any issue (e.g. #2190, #2115).
We’ve improved installation options, letting you configure things that may be important in a production environment, like setting toleration or using a secured maven repository. At the same time, we’ve fixed compatibility with recent dev environments, e.g. letting you smoothly install Camel K in K3S.
We also kept doing changes to continuously improve speed. On the runtime side of Camel K, we now use the Quarkus fast-jar format to reduce boot times. And last but not least on the operator side, it’s possible to install Camel K globally in a cluster and have much faster build times by sharing base images across the cluster.
The list of important changes in the 1.4.0 release is too long for this blog post. There have never been so many contributors as in this release and we thank them all for their awesome work!