Kamelets are the most important feature released with Apache Camel K 1.2.0. Apart from their cool name, Kamelets represent a significant change in the whole Camel ecosystem, because they introduce new ways of using Apache Camel in the cloud and a novel approach for contributing new connectors.
What is a Kamelet?
A Kamelet is a “Kamel Route Snippet”. Before going into the details of what this actually means, let’s make a step backward to add some background context.
Traditionally, the building blocks of Apache Camel have always been the components. Camel users can write complex routes by leveraging the 350+ components that are available in Apache Camel. It’s not a fixed pool: Camel developers and contributors are constantly increasing the collection of supported components at each new release.
This model has worked very well for all these years and it will continue to work. But it misses an important feature that we want to cover with Kamelets: the ability to abstract.
In Camel, if I want to publish a tweet in response to a Knative event, I’d do something like this:
from('knative:event/public.post')
.to('twitter-timeline://user')
Every time some application sends an event of type “public.post” to the Knative broker, that event is published in my Twitter timeline.
As a user, I don’t care about what the “twitter-timeline” component is doing under the covers: it may contact a single API, or more than one, or it may establish several connections to various systems using strange protocols. I’m only interested in the result.
Now, being an enterprise user, I would like to do a similar thing with my own systems and create a new component to add an item to the inventory of my e-commerce application. I decide to create a new component named “company-inventory” that provides an “add” endpoint to implement such feature. So:
from('knative:event/new.item')
.to('company-inventory://add') // easy, but now try to implement it
Now it’s time to implement the “company-inventory” component. When adding an item to the inventory, we need to call an HTTP API to get the ID of the actual item type, call another API if the ID is not already present, in order to create a new one, then a third API to add the item, then add another event to a third-party Kafka topic to synchronize downstream services.
Easy? Of course, with Apache Camel. But guess what? You can’t use Apache Camel when writing a new component.
True. Developers who contribute code to Apache Camel usually adapt existing libraries to the Camel APIs, but they can’t leverage existing components. There’s been an attempt in Camel 2.x to bring such possibility with the Routebox component, but it was not intuitive in some parts and missed a good delivery model, so it wasn’t widely used and it was finally removed in 3.x in favor of this new idea of Kamelets.
Kamelets come to the rescue. With Kamelets you can encapsulate the logic to connect to a specific system into route templates (new feature of Camel 3.5.0). And guess what? Kamelets are made of pure Camel DSL.
Kamelets are Kubernetes resources. We’ll see shortly how to write them. As any Kubernetes resource, you can write a Kamelet into a file and install it on a cluster using Kubectl:
company-inventory-add.kamelet.yaml
apiVersion: camel.apache.org/v1alpha1
kind: Kamelet
metadata:
name: company-inventory-add
spec:
# ...
# The Kamelet will declare all accepted parameters
# in JSON-schema format.
#
# Skipping the details here.
# ...
flow: # Here's the route
from:
uri: "kamelet:source"
steps:
- to: "http://first-endpoint"
- to: "https://second-endpoint/{{itemType}}"
- choice:
# ...
- to: "kafka:downstream"
I’m not going into the details of how to write a Kamelet, that is covered in the Camel K user guide about Kamelets. We need just to know that:
- A Kamelet exposes a well defined JSON-schema interface, that documents its purpose and defines the accepted parameters.
- A Kamelet can be a source of data or a sink (consumer or producer, in the Camel jargon). The “company-inventory-add” Kamelet is a sink.
- A Kamelet defines what Camel code should be executed when the Kamelet is used inside an integration: the code is expressed as route template that can use properties (e.g. “{{itemType}}”)
You can install the Kamelet on a namespace by simply executing:
kubectl apply -f company-inventory-add.kamelet.yaml
Once done so, the Kamelet becomes available in all integrations that are deployed in the same Kubernetes namespace. So you can write a route like this to use the Kamelet:
example.groovy
from('knative:event/new.item')
.to('kamelet://company-inventory-add?itemType=grocery') // implementing this is much simpler
And run it with:
kamel run example.groovy
The logic about what it means to add an inventory item is encapsulated in the Kamelet (multiple HTTP calls, enterprise integration patterns and sync with Kafka), that can be shared among all other integrations. And it’s all Camel DSL.
This is only a simple example of what a Kamelet can do, there are many more interesting use cases out there.
What about Knative sources?
The first time we thought about Kamelets was in the context of Knative Eventing sources. It was the end of 2018, believe it or not. We thought that they could really make the difference in that space, but we were not ready for the leap.
We are currently providing CamelSources in Knative, and they are really cool because they allow users to write a small piece of Camel DSL to produce any kind of event, taking data from any system that Camel supports.
So, what’s wrong with CamelSources? They are really cool from my point of view. But the problem is that Knative users are usually not Camel users. As a Camel user, I can write a piece of Camel DSL in a few minutes and make it work. But people with a background in Go or Python… they don’t even know what Camel actually is.
But that’s where a Kamelet can help.
Camel developers and passionate contributors will write the Camel DSL, creating “connectors” for external sources using the language of Kamelets. In future versions of Camel K, we’ll create a catalog of curated Kamelets that will be installed together with Camel K. Those Kamelets will be available to anyone who installs Camel K on a Kubernetes cluster.
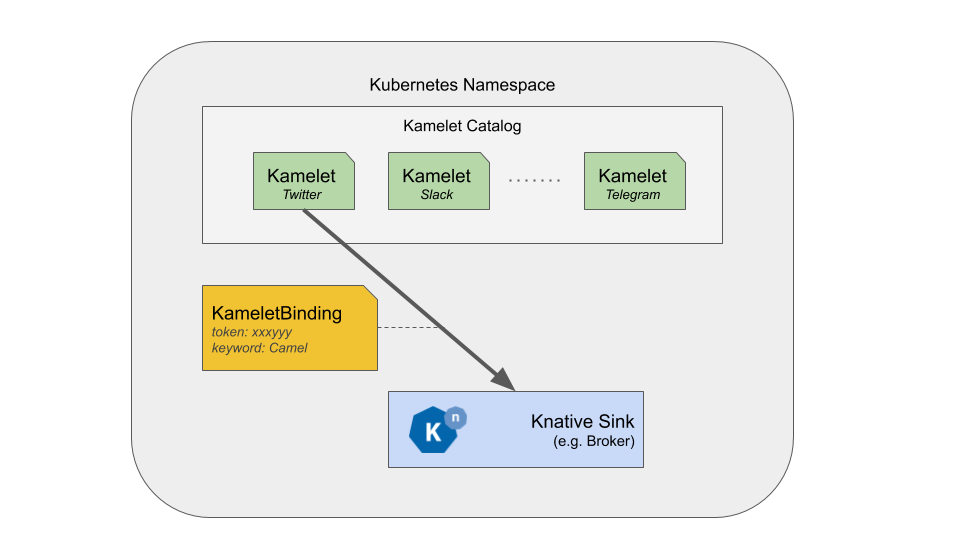
Without any knowledge of Apache Camel, people can list the catalog of the available Kamelets with standard Kubernetes tools:
$ kubectl get kamelets
NAME
inventory-source
twitter-source
slack-source
telegram-source
...
Kamelets declare the list of expected parameters using a JSON-schema format, so it will be easy to check them and provide values.
Users can then decide to use a Kamelet e.g. to push some twitter data into the Knative broker. To do so, they can create a KameletBinding.
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: twitter-source-to-knative
spec:
source:
ref:
apiVersion: camel.apache.org/v1alpha1
kind: Kamelet
name: twitter-source
properties:
keywords: Apache Camel
sink:
ref:
apiVersion: eventing.knative.dev/v1
kind: Broker
name: default
As you see, the final user will not need to know anything about Camel, only use the source.
Of course, the KameletBinding resource is a wrapper for an Integration. I.e. under the hood the operator will create the Camel DSL corresponding to the binding, which is something like:
# only for demonstration, we don't generate groovy code ;)
from('kamelet:twitter-source?keywords=Apache+Camel')
.to('knative:event')
This makes Kamelets available to different kind of users: Camel users and Knative users, with a different interface.
So, is it only about Knative?
Of course not: Kamelets are general purpose connectors, not directly linked to Knative.
If I want to send data from my Twitter Kamelet to a Kafka topic, I just need to create the following code and run it:
from('kamelet:twitter-source?keywords=Apache+Camel')
.to('kafka:topic')
All Kamelets can be used to feed Kafka instead of Knative with the same exact approach. In fact, we’ve also extended the KameletBinding mechanism to Kafka via Strimzi.
What makes Kamelets great?
The main difference between a Kamelet and a Camel component is its purpose. While a component can serve several purposes by specifying different combinations of the parameters, Kamelets are driven by use cases. A Kamelet can let you perform a specific action on a system or gather data from another system, with a limited degree of flexibility.
Reducing the scope helps designing CLI or UI tools around them.
A Kamelet contains (see the Kamelet specification for more details):
- Title and description of the purpose of the Kamelet and how to use it
- A nice icon
- The set of expected parameters in JSON-schema format
- The schema of the output they produce (or the input they require)
- Implementation (Camel DSL)
Writing a UI that allows browsing the available Kamelets, configure them and bind them to a destination should be pretty easy.
There are many possible use cases:
- A specialized UI, e.g. in the OpenShift dev console, can let the user browse the available Kamelets and configure them via a graphical form to send data to a particular Knative destination
- A second specialized UI about Kafka can include a section where the users can instantiate the Kamelets to bring data to a particular topic
- Another platform, e.g. like Syndesis can use the Kamelets to provide additional connectors for creating end-to-end integrations
The great thing about Kamelets is that they are not bound to a spcific technology: they are reusable connectors.
Try them out!
Camel K 1.2.0 has already been released, so, why don’t you try this new feature?
Feedback is welcome, as well as any kind of contribution!
Meet us on Zulip!