Knative is an open source project for adding serverless building blocks on Kubernetes and it’s constantly gaining traction among developers. In Apache Camel K, we’ve been working hard to leverage all the new possibilities that it provides and this article will show the results we’ve achieved so far.
If you’re not familiar with Camel K, you can read the introductory blog post. Camel K provides a lot of new features when running on Knative, but it also runs on plain “vanilla” Kubernetes and OpenShift.
Let’s start with the demo, then you can read the rest of the article to understand better what we’re doing.
So, what is Knative? (and what is not)
Knative is not a complete serverless platform. Nor it’s going to become one.
Knative provides a collection of Kubernetes “Custom Resource Definitions” (CRD)
together with related controllers that make it easier to build and deploy certain kind of applications
on Kubernetes.
Knative building blocks can be roughly divided into 3 major areas.
The Knative Build area provides custom resources for building applications from source code and producing container images.
The CRDs provided in Knative Serving area allow to define services that that scale automatically based on the load. Services can expose generic HTTP endpoints (such as REST): they are not necessarily “functions” (as in FaaS). These services can scale up when the load increases, but also scale down to zero when the load is absent for a certain amount of time. Services that are scaled down to zero don’t consume physical resources and they are brought up again as soon as they need to serve a new request.
The last part of Knative I’m going to describe (and the most important one for our purposes) is the Knative Eventing area.
The Eventing Model
Knative Eventing provides a set of building blocks (CRD) for developing event-based applications.
The main block is the Channel. A channel is the abstraction of a publish-subscribe resource: you can push data into the channel, other services can subscribe to it to receive your data. The channel also decouples producers and consumers, so that producers can always push data into them and consumers can do processing when they are available.
Channels can be backed by different implementations. You can use a “in-memory” implementation, but also a complex one: currently Kafka, GCP PubSub or Nats. Those are referred as provisioners in the Knative area.
You may ask now: why don’t we just use Kafka or Nats directly, what’s the value added by Knative?
Just look at this schema.
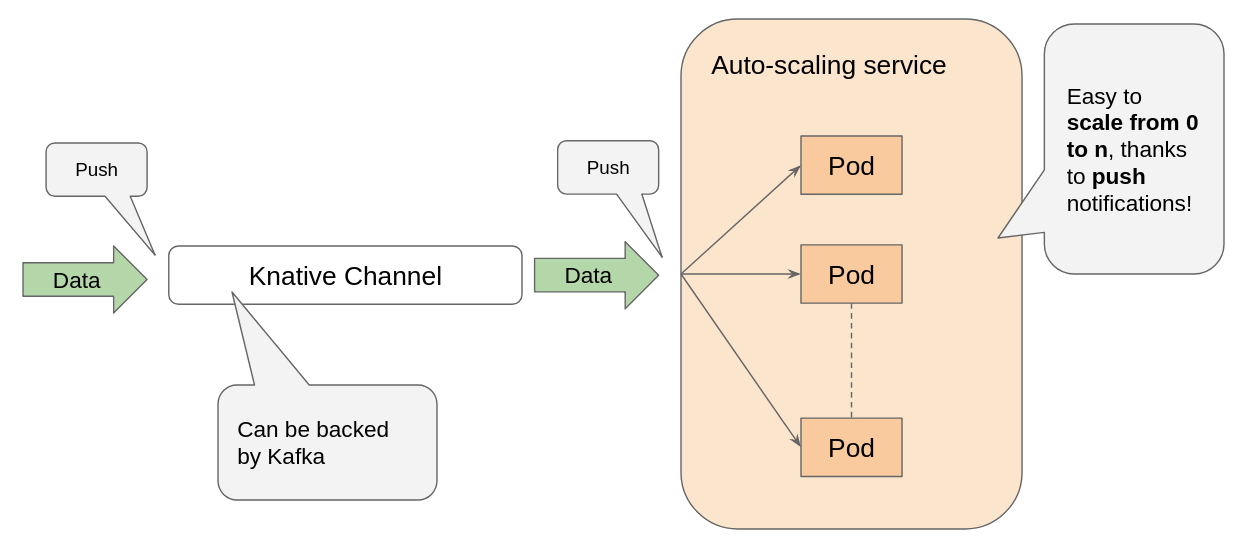
You can notice that the relationship between the channel and the service is somewhat reversed respect to a classical scenario.
Normally, you define a service so that when it starts it connects to a messaging broker and start pulling data
from within that connection. In Knative eventing, you subscribe to a channel (using a specific Subscription CRD), then it’s the channel that pushes events towards your service.
The nice thing of all this, is that your service just receives messages through incoming Cloudevents, without having to actively connect to the broker. Your service becomes passive. And since Knative provides other building blocks for autoscaling, your service scales up and down with the number of events in the channel to which it’s subscribed. Scaling to zero is included.
Another important building block in the Knative Eventing space is the concept of EventSource. A event source is a resource with the role of pushing data into a Channel. E.g. you can use a GithubSource to foward GitHub generated webhook events into a channel.
Current plan in Knative is to start adding as many EventSources as possible and this is one of the places where Camel and Camel K can do the difference. Camel is already able to connect to 250+ different systems. And Camel is also famous for the variety of enterprise integration patterns (EIP) it implements: EIPs are really important in scenarios enabled by Knative Eventing.
How Camel K works
I’ve already described some of the internals of Camel K in the introductory blog post and there will be more blog posts from the Camel K developers in the next days (so, stay tuned!).
The basic idea behind Camel K is explained in the following diagram.
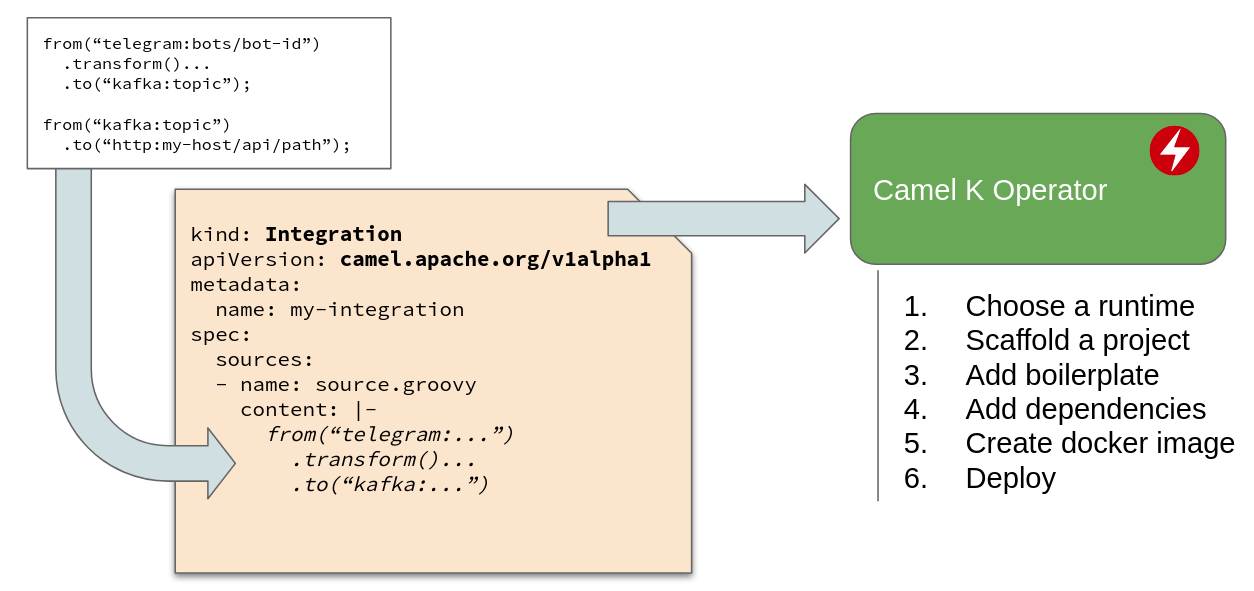
Camel K users write their integration code (the Camel DSL) in a script file, using Groovy, Kotlin, Java or even JavaScript or XML, and run it directly in the cloud platform.
What happens under the hood is that the script is wrapped into a “Integration” Custom Resource and added to a Kubernetes namespace. The Camel K Operator (based on operator SDK) will then detect the new Integration and materialize it into running containers. Normally Camel K materializes an Integration into a Kubernetes Deployment, but when running on Knative, it uses auto-scaling services.
What is really cool about Camel K is that it’s able to materialize and startup integrations in few seconds. This helps a lot during the development phase, because you have immediate feedback on the code you’re writing. The video accompanying the first blog post emphasizes this feature.
Camel K and Knative
Camel K fully supports Knative since version v0.1.0. I often tend to remind (so you don’t forget it) that Camel K can also run on plain (= without Knative) OpenShift and “vanilla” Kubernetes, but without “serverless features”.
An important thing of the Knative model is that, since Knative is not a serverless platform, but a set of building blocks, you can run on top of Knative even multiple serverless platforms. Knative does not only provide the building blocks for creating auto-scaling services, but also the building blocks for those platforms to communicate with each other (eventing).
Camel K, thus, is not intended to run as exclusive serverless platform on top of Knative, it’s rather a serverless integration layer.
You are not expected to build generic functions with Camel, you can just use your FaaS platform to do it (provided that it works on top of Knative). But there are at least three places where using Camel K is the best choice you can do.
1. Camel K for creating Event Sources
Camel can easily push data into Knative channels, acting as event source.
We’ve added a new component in Camel K named “knative”, that allows publishing and subscribing to knative channels. You can use a Knative endpoint at the end of any route to create a event source. And you can use any combination of the 250+ Camel components as starting point.
For example, in the demo you’re going to see the following route:
from('telegram:bots/<put-here-your-botfather-authorization>')
.convertBodyTo(String.class)
.to('knative:channel/messages')
You can run it by simply executing kamel run telegram-feed.groovy. As already mentioned, kamel is used to
simply wrap the code in a Kubernetes custom resource, while the materialization work is always accomplished inside
Kubernetes by the Camel K Operator.
The simple script above generates a “event source”: an integration that forwards all messages sent to a specific bot on telegram to the “messages” Knative channel.
2. Camel K for Enterprise Integration Patterns (EIP)
Camel K can also be used within Knative for its powerful enterprise integration patterns. You will see in the demo the following integration:
from('knative:channel/messages')
.split().tokenize(" ")
.to('knative:channel/words')
It is an example of one of the simplest EIP available in Camel, the splitter EIP.
You run this integration as usual: kamel run splitter.groovy.
In Camel you have tons of EIP that you can use out-of-the-box, even within Knative: content-based router, dynamic router, message filter, message transformation, recipient list… and many others.
3. Camel K for defining Integration Functions
Many times you need to notify an external system that an event occurred in the serverless space. In these cases, it’s likely that you’ll write an integration function that gets executed when a specific event is received from a channel.
In the demo, you’ll se something like:
from('knative:channel/words')
.to('slack:#camel-k-tests')
This integration snippet is simply forwarding text messages to a Slack channel, but it could be also be doing transformations or enriching content with external data.
Future Work
Camel K runs really well on Knative, but we want to provide a even better experience in the next months.
The value that Camel K adds to Knative is a easy way for people to write EventSources, EIP and Integration Functions. We need to enable people to just do that, but in a way that fits more closely the ideas that are being developed within the Knative space.
The roadmaps of Camel K and Knative are closely related.
Apache Camel K is already here. Grab it while it’s hot!